精通Python爬虫框架Scrapy.pdf
”Python 爬虫 Python 爬虫框架 Python 爬虫框架 Scrapy“ 的搜索结果
本教程将实际操作使用Python Scrapy框架爬取传智播客教师页面教师的个人信息。 爬取页面网址:http://www.itcast.cn/channel/teacher.shtml#ac Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于...
Python爬虫是一种使用Python编程语言来自动化获取网页数据的技术。这项技术主要涉及到向目标服务器发送请求,获取HTML页面内容,然后通过解析HTML来提取所需的数据。Python爬虫在数据收集、网络监测、自动化测试等...


pythonscrapy爬虫实例Python爬虫Scrapy实例
精通python爬虫框架scrapy源码修改原始码可编辑python3版本 本书涵盖了期待已久的Scrapy v 1.0,它使您能够以极少的努力从几乎任何来源中提取有用的数据。 首先说明Scrapy框架的基础知识,然后详细说明如何从任何...
本文实例讲述了python爬虫框架scrapy实现模拟登录操作。分享给大家供大家参考,具体如下: 一、背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML、json数据,但是忽略了很多的一个问题,有很...
解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫

本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索’python’关键字, 在浏览器地址栏可以看到搜索结果页的url为...
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
大家好我是小菜鸡,让我们一起学习Python的网络爬虫框架-Scrapy爬虫框架的使用(一起努力,咱们顶峰相见!!!)
《Python爬虫框架Scrapy教程》主要是针对学习python爬虫的课程,又基础的python爬虫框架scrapy开始,一步步学习到最后完整的爬虫完成,现在python爬虫应用的非常广泛,本文档详细介绍了scrapy爬虫和其他爬虫技术的...
基础的框架,适合入门选手
python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python ...
新建项目(命令行:scrapy startproject xxx):新建一个爬虫项目 明确目标(编写items.py):明确你想要抓取的目标 制作爬虫(spiders/xxspider.py):制作爬虫开始爬取网页 存储内容(pipelines.py):设计管道...
主要给大家介绍了利用python爬虫框架scrapy爬取京东商城的相关资料,文中给出了详细的代码介绍供大家参考学习,并在文末给出了完整的代码,需要的朋友们可以参考学习,下面来一起看看吧。
本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式...这些文件详细展示了如何使用Python和Scrapy框架构建基础爬虫,以及如何使用Scrapy-Redis实现分布式爬虫,非常适合用于学习和参考Python项目的开发。
主要介绍了Python爬虫框架Scrapy常用命令,结合实例形式总结分析了Scrapy框架中常见的全局命令与项目命令功能、使用方法及操作注意事项,需要的朋友可以参考下
一、创建Scrapy项目 scrapy startproject Tencent 命令执行后,会创建一个Tencent文件夹,结构如下 二、编写item文件,根据需要爬取的内容定义爬取字段 # -*- coding: utf-8 -*- import scrapy class TencentItem...
python爬虫学习 scrapy框架 爬虫学习 scrapy python爬虫学习 scrapy框架 爬虫学习 scrapy python爬虫学习 scrapy框架 爬虫学习 scrapypython爬虫学习 scrapy框架 爬虫学习python爬虫学习 scrapy框架 爬虫学习python...
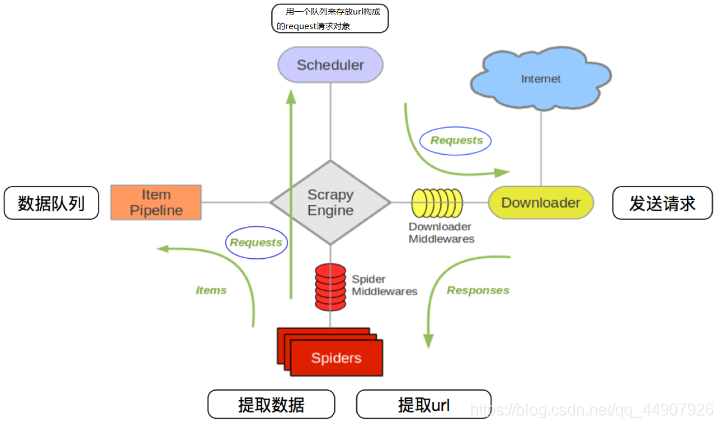
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Python爬虫框架Scrapy详细介绍
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
本源码提供了一个基于Python的Scrapy爬虫框架设计。项目包含20个文件,其中包括6个Python字节码文件、6个Python源文件、3个XML文件、1个Gitignore文件、1个IML文件、1个CSV文件、1个TXT文件和1个CFG文件。这个项目是...
推荐文章
- pytorch基础 神经网络构建-程序员宅基地
- 怎样实现c#生成的exe文件脱离Halcon的安装环境运行_c#如何免安装halcon12-程序员宅基地
- 发现电脑一直默认按住Ctrl键如何解决_键盘一直自动按ctrl-程序员宅基地
- Linux 命令【6】:cut_cut使用特殊字符为分隔符-程序员宅基地
- 音频进度条设置_audiotrack可以设置进度吗-程序员宅基地
- Sora----打破虚实之间的最后一根枷锁----这扇门的背后是人类文明的晟阳还是最后的余晖-程序员宅基地
- 大批量数据分批式导出文件解决,避免OOM(多次查询多次导出形成一个文件)_bufferedwriter避免oom-程序员宅基地
- 如何生成HLS协议的M3U8文件-程序员宅基地
- Oracle游标:处理查询结果集的好工具_oracle查询游标结果集-程序员宅基地
- 计算机主机箱内的硬件设备主要有哪些,电脑主机有哪些硬件设备-程序员宅基地